如何保持資料庫跟緩存的最終一致性
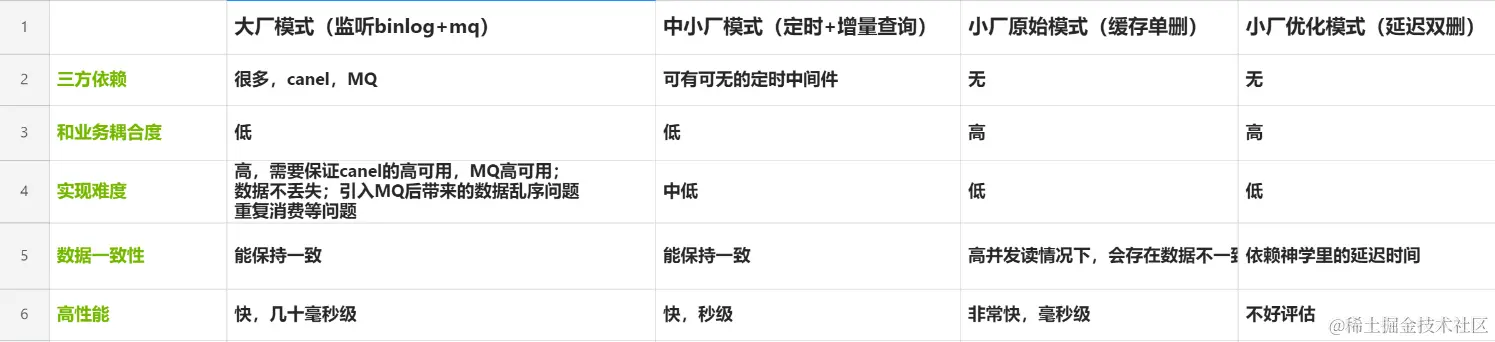
監聽 binlog+mq (大廠模式)
大廠模式主要是透過監聽資料庫的 binlog(例如 mysql binlog);透過 binlog 把資料庫資料的更新作業日誌(例如 insert,update,delete),收集到後,透過 MQ 的方式,把資料同步到下游對應的消費者;下游消費者拿到資料的操作日誌並拿到對應的業務資料後,再放入快取。
大概流程圖:

優點:
1.把操作快取的程式碼邏輯,從正常的業務邏輯解耦出來;業務代碼更清爽簡潔,兩者互不干擾和影響,獨立發展。用非人類的話來說,減少對業務代碼的侵入性。
2.曾經有幸在大廠裡實踐過此種方案,速度還賊快,雖然從庫到緩存經過了類 canal 和 mq 中間件,但基本上耗時都是在毫秒級,99.9%都是 10 毫秒內能完成庫裡的資料和快取資料同步(大廠的優勢出來了)
缺點:
1、技術方案和架構,非常複雜
2、中間件的運維和維護,是個不小的工作量
3、由於引入了 MQ 需要解決引入 MQ 後帶來的問題。例如資料亂序問題
定時 + 增量查詢 (中小廠模式)
定時更新+增量查詢:主要利用庫裡行資料的更新時間欄位+定時增量查詢。
具體為:每次更新庫裡的行數據,記錄當前行的更新時間;然後把更新時間做為一個索引字段(加快查詢速度嘛)
定時任務:會每隔 5 秒鐘(間隔時間可自訂);把庫裡最近更新 5 秒鐘的資料查詢出來;然後放入緩存,並記錄本次查詢結束時間。
整個查詢過程和放入快取的過程都是單執行緒執行;所以不會有併發更新快取問題。另外每次同步成功後,會記錄同步成功時間;下次定時任務再執行時,會拿上次同步成功時間,做為本次查詢開始時間條件;當前時間做為查詢結束時間,以此達到增量查詢的目標。
優點:
1、實作方案,和架構很簡單。是的,比起大廠那套方案,簡直不要太輕。
2.也能把快取邏輯和業務邏輯解耦
3、三方依賴也比較少。如果有條件可以上個分散式定時中間件例如 xxl-job,實在不行就用 redis 做個分散式鎖也能用
缺點:
1、資料庫裡的數據和快取中數據,會在極短時間內,存在不一致,但最終會是一致的。這個極短的時間,取決於定時調度間隔時間,一般在秒級。
2.如果是分庫分錶的業務,寫這個查詢邏輯,估計會稍微複雜一點。
如果業務上不是要求毫秒級的及時性,也不是類似於價格這種非常敏感的數據,這種輕量級方案還真不錯。無併發問題,也無資料亂序問題;秒級資料量超過幾十萬的增量資料並且還需要快取的,怕是只有大廠才有的場景吧;怎麼看此方案都非常適合中小公司。
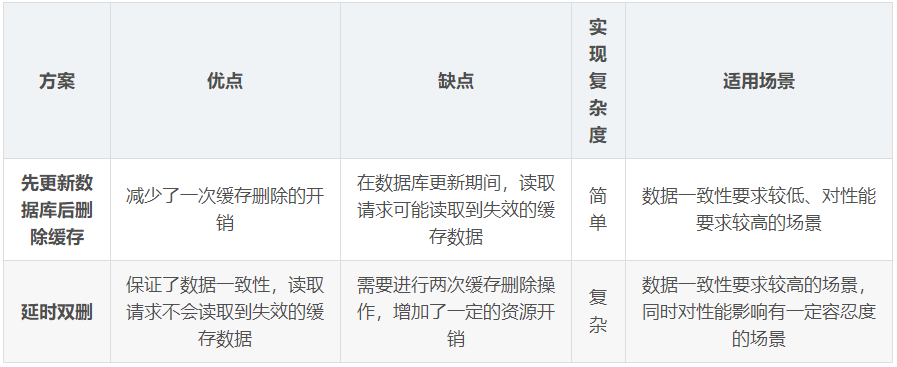
先更新資料庫再刪緩存 (小廠模式)
那麼「先更新資料庫再刪除緩存」一定不會有資料不一致的問題嗎?繼續用「讀+ 寫」請求的併發的場景來分析:
-
假如某個用戶資料在緩存中不存在,請求 A 讀取資料時從資料庫中查詢到年齡為 20。
-
未寫入緩存時另一個請求 B 更新資料。請求 B 更新資料庫中的年齡為 21,並且清空緩存。
-
這時請求 A 把從資料庫中讀到的年齡為 20 的資料寫入到緩存中。
-
最終,該用戶年齡在緩存中是 20(舊值),在資料庫中是 21(新值),緩存和資料庫資料不一致。

從上面的理論上分析,先更新資料庫,再刪除緩存也是會出現資料不一致性的問題,但是在實際中,這個問題出現的機率並不高。這主要有以下原因:
-
緩存的寫入通常遠遠快於資料庫的寫入。
-
所以在實際中很難出現請求 B 已經更新了資料庫並且刪除了緩存,請求 A 才更新完緩存的狀況。
-
而一旦請求 A 早於請求 B 刪除緩存之前更新了緩存,那麼接下來的請求就會因為緩存不命中而從數據庫中重新讀取數據,所以一般不會出現這種不一致的情況。
延遲雙刪 (小廠模式)
這裡指的是刪除兩次緩存,首先刪除緩存,然後更新資料庫,為了避免有其他的請求拿錯誤的數據覆蓋到了緩存,再次刪除掉緩存,讓下一次的請求命中到數據庫,從而把最新的數據填充到緩存。
但為什麼會有延遲呢,普通的雙刪時,假設 B 請求獲取到了舊數據,準備填充到緩存,A 請求剛剛更新完數據庫,立刻刪除了緩存,在刪除完成後 B 請求才把舊數據去填充,這樣仍會出現緩存與資料庫不一致的情況(即緩存內資料錯誤)。
比較