如何使用索引
什麼時候需要 / 不需要創建索引?
索引最大的好處是提高查詢速度,但是索引也是有缺點的,比如:
- 需要佔用物理空間,數量越大,佔用空間越大
- 創建索引和維護索引要耗費時間,這種時間隨著數據量的增加而增大
- 會降低表的增刪改的效率,因為每次增刪改索引,B+ 樹為了維護索引有序性,都需要進行動態維護
所以,索引不是萬能鑰匙,它也是根據場景來使用的。
什麼時候適用索引?
- 字段有唯一性限制的,比如商品編碼
- 經常用於
WHERE查詢條件的字段,這樣能夠提高整個表的查詢速度,如果查詢條件不是一個字段,可以建立聯合索引 GROUP BY和ORDER BY的字段,這樣在查詢的時候就不需要再去做一次排序了,因為我們都已經知道了建立索引之後在 B+Tree 中的記錄都是排序好的
什麼時候不需要創建索引?
WHERE條件,GROUP BY,ORDER BY裡用不到的字段,索引的價值是快速定位,起不到定位的字段通常是不需要創建索引的,因為索引是會佔用物理空間的- 字段中存在大量重複數據,不需要創建索引,比如性別字段,只有男女,如果數據庫表中,男女的記錄分佈均勻,那麼無論搜索哪個值都可能得到一半的數據。在這些情況下,還不如不要索引,因為 MySQL 還有一個查詢優化器,查詢優化器發現某個值出現在表的數據行中的百分比很高的時候,它一般會忽略索引,進行全表掃描
- 表數據太少的時候,不需要創建索引
- 經常更新的字段不用創建索引,比如不要對電商項目的用戶餘額建立索引,因為索引字段頻繁修改,由於要維護 B+Tree 的有序性,那麼就需要頻繁地重建索引,這個過程是會影響數據庫性能的
聯合索引
通過將多個字段組合成一個索引,該索引就被稱為聯合索引 (或複合索引)。
比如,將商品表中的 product_no 和 name 字段組合成聯合索引 (product_no, name),創建聯合索引的方式如下:
CREATE INDEX index_product_no_name ON product(product_no, name);
聯合索引 (product_no, name) 的 B+Tree 示意圖如下:
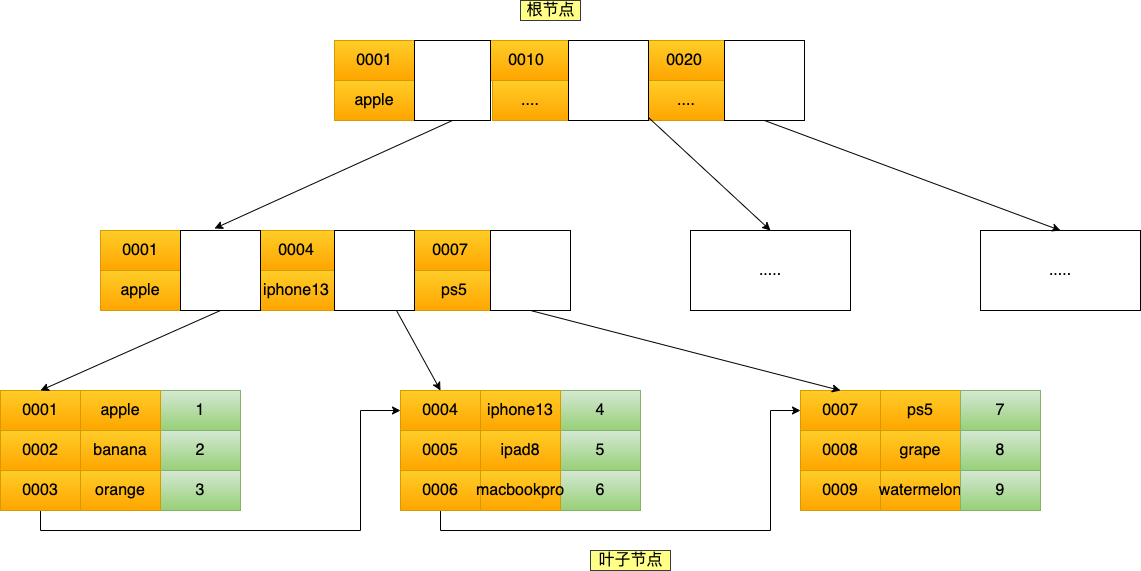
可以看到,聯合索引的非葉子節點用兩個字段的值作為 B+Tree 的 key 值。當在聯合索引查詢數據時,先按 product_no 字段比較,在 product_no 相同的情況下再按 name 字段比較。
也就是說,聯合索引查詢的 B+Tree 是先按 product_no 進行排序,然後在 product_no 相同的情況再按 name 字段排序。
因此,使用聯合索引時,存在最左匹配原則,也就是按照最左優先的方式進行索引的匹配。在使用聯合索引進行查詢的時候,如果不遵循「最左匹配原則」,聯合索引會失效,這樣就無法利用到索引快速查詢的特性了。
比如,如果創建了一個 (a, b, c) 聯合索引,如果查詢條件是以下這幾種,就可以匹配上聯合索引:
- where a = 1
- where a = 1 and b = 2
- where a = 1 and b = 2 and c = 3
需要注意的是,因為有查詢優化器,所以 a 字段在 where 子句的順序並不重要。
但是,如果查詢條件是以下這幾種,因為不符合最左匹配原則,所以就無法匹配上聯合索引,聯合索引就會失效:
- where b = 2
- where c = 3
- where b = 2 and c = 3
上面這些查詢條件之所以會失效,是因為 (a, b, c) 聯合索引,是先按 a 排序,在 a 相同的情況再按 b 排序,在 b 相同的情況再按 c 排序。所以,b 和 c 是全局無序,局部相對有序的,這樣在沒有遵循最左匹配原則的情況下,是無法利用到索引的。
我這裡舉聯合索引(a,b)的例子,該聯合索引的 B+ Tree 如下:
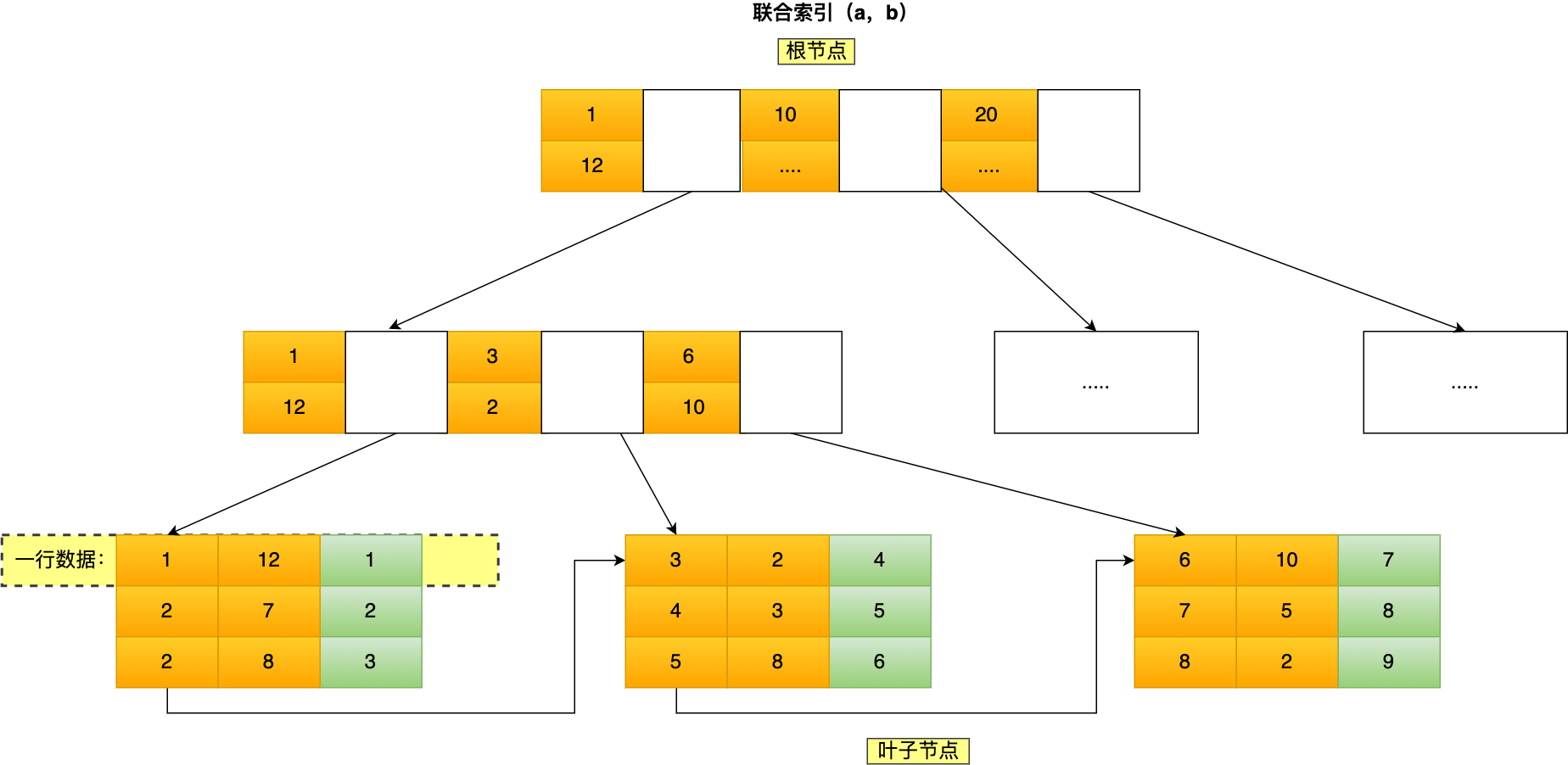
可以看到,a 是全局有序的(1, 2, 2, 3, 4, 5, 6, 7 ,8),而 b 是全局是無序的(12,7,8,2,3,8,10,5,2)。因此,直接執行 where b = 2 這種查詢是沒有辦法利用聯合索引的,利用索引的前提是索引裡的 key 是有序的。
只有在 a 相同的情況才,b 才是有序的,比如 a 等於 2 的時候,b 的值為(7,8),這時就是有序的,這個有序狀態是局部的,因此,執行 where a = 2 and b = 7 a 和 b 字段是能用到聯合索引的。
聯合索引範圍查詢
聯合索引有一些特殊情況,並不是查詢過程使用了聯合索引查詢,就代表聯合索引中的所有字段都用到了聯合索引進行查詢,也就是可能存在部分字段用到聯合索引,部分字段沒有用到聯合索引的情況。
這種特殊情況就發生在範圍查詢。聯合索引的最左匹配原則會一直向右匹配直到遇到「範圍查詢」就會停止匹配。也就是範圍查詢的字段可以用到聯合索引,但是在範圍查詢字段的後面的字段無法用到聯合索引。
範圍查詢有很多種,那到底是哪些範圍查詢會導致聯合索引的最左匹配原則會停止匹配呢?
Q1
select * from t_table where a > 1 and b = 2
由於聯合索引(二級索引)是先按照 a 字段的值排序的,所以符合 a > 1 條件的二級索引記錄肯定是相鄰,於是在進行索引掃描的時候,可以定位到符合 a > 1 條件的第一條記錄,然後沿著記錄所在的鍊錶向後掃描,直到某條記錄不符合 a > 1 條件。
但是在符合 a > 1 條件的二級索引記錄的範圍裡,b 字段的值是無序的。
下面這三條記錄的 a 字段的值都符合 a > 1 查詢條件,而 b 字段的值是無序的:
- a 字段值為 5 的記錄,該記錄的 b 字段值為 8
- a 字段值為 6 的記錄,該記錄的 b 字段值為 10
- a 字段值為 7 的記錄,該記錄的 b 字段值為 5
因此,我們不能根據查詢條件 b = 2 來進一步減少需要掃描的記錄數量。
在執行 Q1 這條查詢語句的時候,對應的掃描區間是 (2, + ∞),形成該掃描區間的邊界條件是 a > 1,與 b = 2 無關。
舉個例子,a 和 b 都是 int 類型且不為 NULL 的字段,那麼 Q1 這條查詢語句執行計劃如下,可以看到 key_len 為 4 字節(如果字段允許為 NULL,就在字段類型占用的字節數上加 1,也就是 5 字節),說明只有 a 字段用到了聯合索引進行索引查詢。

Q2
select * from t_table where a >= 1 and b = 2
Q2 和 Q1 的查詢語句很像,唯一的區別就是 a 字段的查詢條件「大於等於」。
由於聯合索引(二級索引)是先按照 a 字段的值排序的,所以符合 >= 1 條件的二級索引記錄肯定是相鄰,於是在進行索引掃描的時候,可以定位到符合 >= 1 條件的第一條記錄,然後沿著記錄所在的鍊錶向後掃描,直到某條記錄不符合 a >= 1 條件位置。所以 a 字段可以在聯合索引中進行索引查詢。
雖然在符合 a >= 1 條件的二級索引記錄的範圍裡,b 字段的值是「無序」的,但是對於符合 a = 1 的二級索引記錄的範圍裡,b 字段的值是「有序」的(因為對於聯合索引,是先按照 a 字段的值排序,然後在 a 字段的值相同的情況下,再按照 b 字段的值進行排序)。
於是,在確定需要掃描的二級索引的範圍時,當二級索引記錄的 a 字段值為 1 時,可以通過 b = 2 條件減少需要掃描的二級索引記錄範圍。也就是說,從符合 a = 1 and b = 2 條件的第一條記錄開始掃描,而不需要從第一個 a 字段值為 1 的記錄開始掃描。
因此,Q2 這條查詢語句 a 和 b 字段都用到了聯合索引進行索引查詢。

Q3
SELECT * FROM t_table WHERE a BETWEEN 2 AND 8 AND b = 2
Q3 查詢條件中 a BETWEEN 2 AND 8 的意思是查詢 a 字段的值在 2 和 8 之間的記錄。不同的數據庫對 BETWEEN ... AND 處理方式是有差異的。在 MySQL 中,BETWEEN 包含了 value1 和 value2 邊界值,類似於 >= and =<。而有的數據庫則不包含 value1 和 value2 邊界值(類似於 > and <)。
這裡我們只討論 MySQL。由於 MySQL 的 BETWEEN 包含 value1 和 value2 邊界值,所以類似於 Q2 查詢語句,因此 Q3 這條查詢語句 a 和 b 字段都用到了聯合索引進行索引查詢。

Q4
SELECT * FROM t_user WHERE name like 'j%' and age = 22
由於聯合索引(二級索引)是先按照 name 字段的值排序的,所以前綴為'j' 的 name 字段的二級索引記錄都是相鄰的, 於是在進行索引掃描的時候,可以定位到符合前綴為 'j' 的 name 字段的第一條記錄,然後沿著記錄所在的鍊錶向後掃描,直到某條記錄的 name 前綴不為'j' 為止。
所以 a 字段可以在聯合索引中進行索引查詢,形成的掃描區間是 ['j','k')。注意, j 是閉區間。如下圖:
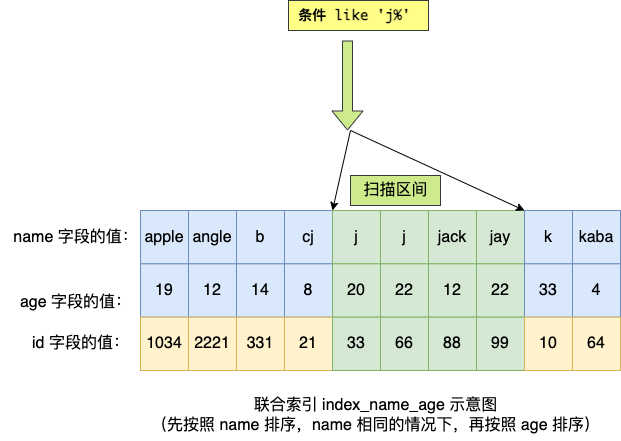
雖然在符合前綴為 'j' 的 name 字段的二級索引記錄的範圍裡,age 字段的值是「無序」的,但是對於符合 name = j 的二級索引記錄的範圍裡,age 字段的值是「有序」的(因為對於聯合索引,是先按照 name 字段的值排序,然後在 name 字段的值相同的情況下,再按照 age 字段的值進行排序)。
於是,在確定需要掃描的二級索引的範圍時,當二級索引記錄的 name 字段值為 'j' 時,可以通過 age = 22 條件減少需要掃描的二級索引記錄範圍。也就是說,從符合 name = 'j' and age = 22 條件的第一條記錄時開始掃描,而不需要從第一個 name 為 j 的記錄開始掃描。如下圖的右邊:
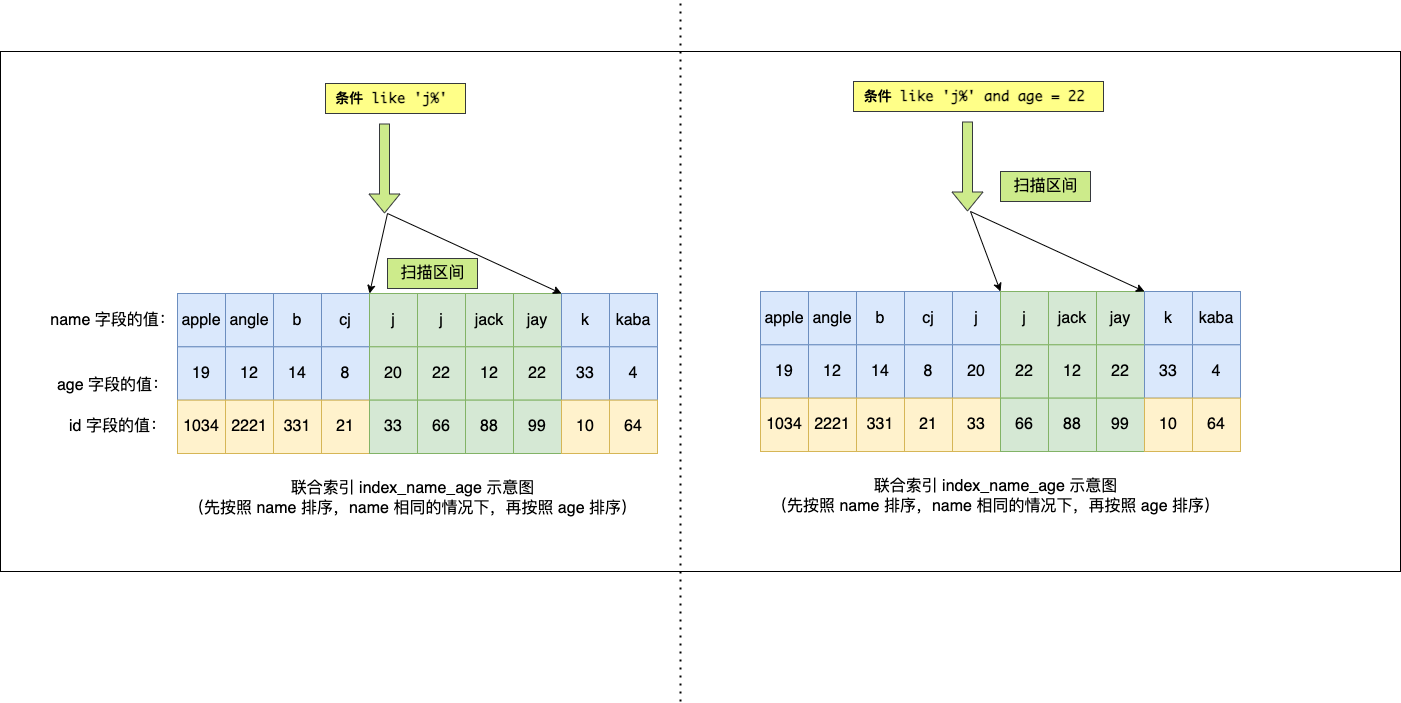
因此,Q4 這條查詢語句 a 和 b 字段都用到了聯合索引進行索引查詢。

綜上所示,聯合索引的最左匹配原則,在遇到範圍查詢(如 >、<)的時候,就會停止匹配,也就是範圍查詢的字段可以用到聯合索引,但是在範圍查詢字段的後面的字段無法用到聯合索引。對於 >=、<=、BETWEEN、like 前綴匹配的範圍查詢,並不會停止匹配。
最大化索引帶來的效益
1. 前綴索引優化
前綴索引顧名思義就是使用某個字段中字符串的前幾個字符建立索引,那我們為什麼需要使用前綴來建立索引呢?
使用前綴索引是為了減小索引字段大小,可以增加一個索引頁中存儲的索引值,有效提高索引的查詢速度。在一些大字符串的字段作為索引時,使用前綴索引可以幫助我們減小索引項的大小。
不過,前綴索引有一定的局限性,例如:
- order by 就無法使用前綴索引
- 無法把前綴索引用作覆蓋索引
2. 覆蓋索引優化
覆蓋索引是指 SQL 中 query 的所有字段,在索引 B+Tree 的葉子節點上都能找得到的那些索引,從二級索引中查詢得到記錄,而不需要通過聚簇索引查詢獲得,可以避免回表的操作。
假設我們只需要查詢商品的名稱、價格,有什麼方式可以避免回表呢?
我們可以建立一個聯合索引,即「商品 ID、名稱、價格」作為一個聯合索引。如果索引中存在這些數據,查詢將不會再次檢索主鍵索引,從而避免回表。
所以,使用覆蓋索引的好處就是,不需要查詢出包含整行記錄的所有信息,也就減少了大量的 I/O 操作。
3. 索引設置為 NOT NULL
為了更好的利用索引,索引列要設置為 NOT NULL 約束。有兩個原因:
- 索引列存在 NULL 就會導致優化器在做索引選擇的時候更加複雜,更加難以優化,因為可為 NULL 的列會使索引、索引統計和值比較更複雜,比如進行索引統計時,count 會省略值為 NULL 的行。
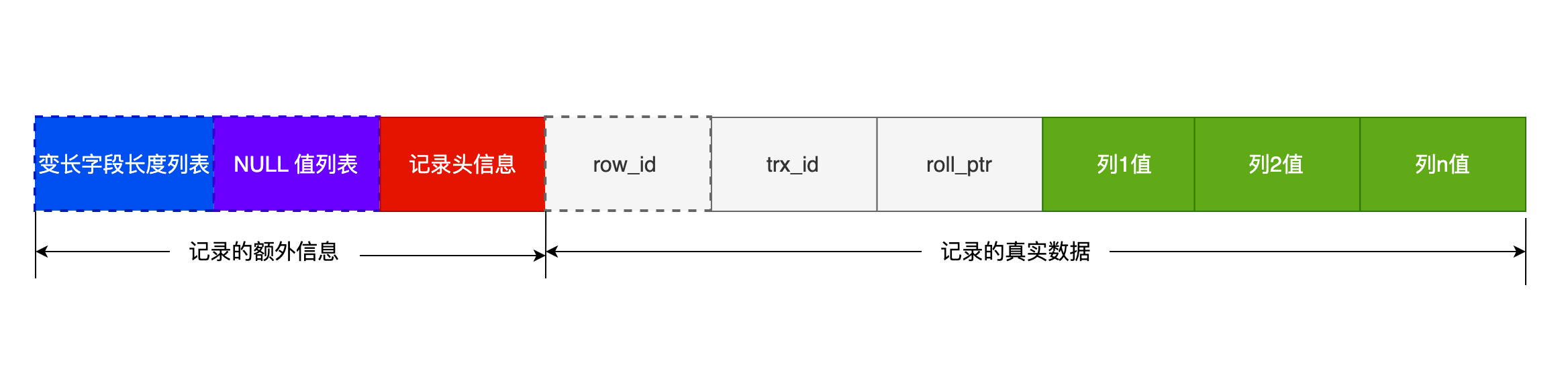
- NULL 值是一個沒意義的值,但是它會佔用物理空間,所以會帶來的存儲空間的問題,因為 InnoDB 存儲記錄的時候,如果表中存在允許為 NULL 的字段,那麼行格式中至少會用 1 字節空間存儲 NULL 值列表,如下圖的紫色部分:
4. 防止索引失效
5. 避免索引碎片化發生
以 MySQL 示範查詢索引的碎片化程度
SELECT table_name AS TABLE_NAME
,table_rows AS TABLE_ROWS
,CONCAT(ROUND(data_length / ( 1024 * 1024), 2), 'MB') AS TB_DATA_SIZE
,CONCAT(ROUND(index_length / ( 1024 * 1024), 2), 'MB') AS TB_IDX_SIZE
,CONCAT(ROUND((data_length + index_length ) / ( 1024 * 1024 ), 2), 'MB') AS TOTAL_SIZE
,CASE WHEN data_length = 0 THEN 0
ELSE ROUND(index_length / data_length, 2)
END AS TB_INDX_RATE
,CONCAT(ROUND( data_free / 1024 / 1024,2), 'MB') AS TB_DATA_FREE
,CASE WHEN (data_length + index_length) = 0 THEN 0
ELSE ROUND(data_free/(data_length + index_length),2)
END AS TB_FRAG_RATE
FROM information_schema.TABLES
WHERE table_schema = 'YOUR_DB_NAME'
ORDER BY data_free DESC;