SQL Query Optimization Tips to Improve Database Performance
1. Proper indexing
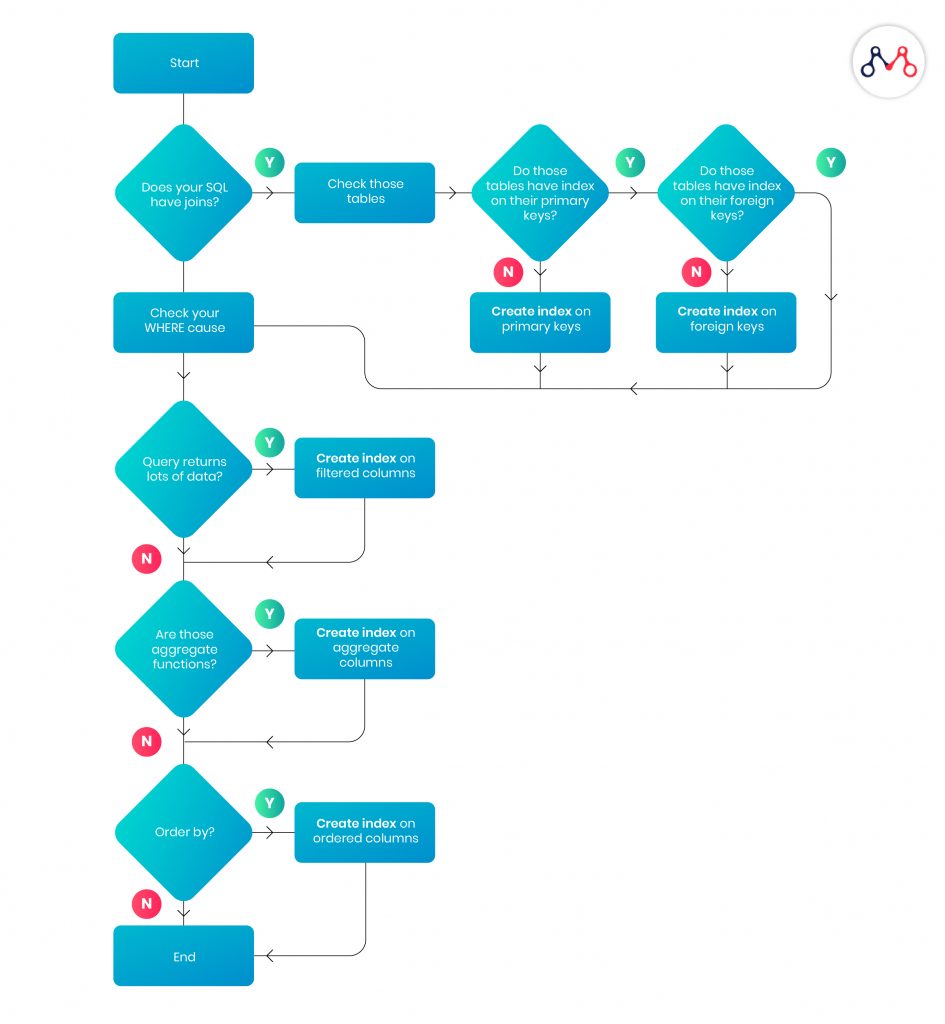
An index is a data structure that improves the speed of data retrieval operations on a database table. A unique index creates separate data columns without overlapping each other. Proper indexing ensures quicker access to the database, i.e. you’ll be able to SELECT or sort rows faster. The following diagram explains the basics of indexing while structuring tables.
2. Avoid running queries in a loop
Coding SQL queries in loops slows down the entire sequence. Instead of writing a query that runs in a loop, you can use bulk insert and update depending on the situation. Suppose there are 1000 records. Here, the query will execute 1000 times.
Inefficient
for ($i = 0; $i < 10; $i++) {
$query = “INSERT INTO TBL (A,B,C) VALUES . . . .”;
$mysqli->query($query);
printf (“New Record has id %d.\\ “, $mysqli->insert\_id);
}
Efficient
INSERT INTO TBL (A,B,C) VALUES (1,2,3), (4,5,6). . . .
3. Replace operator '>' with '>='
Inefficient
SELECT * FROM EMP WHERE DEPTNO > 3
Efficient
SELECT * FROM EMP WHERE DEPTNO >= 4
The difference between the two is that the latter will directly jump to the first record with DEPTNO=4 while the former will first locate the record with DEPTNO=3 and scan forward to the first record with DEPT greater than 3.
4. Avoid null value judgment for the field in the “WHERE” clause
It will cause the engine to give up using the index and perform a full table scan.
SELECT id FROM t WHERE number IS NULL
You can set the default value of 0 on a number to ensure that the num column in the table does not have a null value.
SELECT id FROM t WHERE number IS 0
5. Distinguish between IN and EXISTS
SELECT * FROM form_A WHERE id IN (SELECT id FROM form_B)
The above SQL statement is equivalent to
SELECT * FROM form_A WHERE EXISTS (SELECT 1 FROM form_B WHERE form_B.id = form_A.id)
Distinguishing “IN” and “EXISTS” mainly results in a change in performance. If it is “EXISTS”, then the exterior table is the driving table, which is accessed first. If it is “IN”, then the subquery is executed first. So, “IN” is suitable for the case WHERE the exterior is large and the interior is small; “EXISTS” is suitable for the case WHERE the exterior is small and the interior is large.
6. Avoid using SQL function on the RHS of the operator
Inefficient
SELECT * FROM Customer WHERE YEAR(AccountCreatedOn) = 2005 and MONTH(AccountCreatedOn) = 6
Note that even though AccountCreatedOn has an index, the above query changes the WHERE clause in such a way that this index cannot be used anymore.
Efficient
SELECT * FROM Customer WHERE AccountCreatedOn between ‘6/1/2005’ and ‘6/30/2005’
7. Use subqueries properly
Use subqueries instead of join when you're pulling data from table A based on data from table B but you don't want data from table B to be brought along.
Inefficient
SELECT DISTINCT users.* FROM users
LEFT JOIN posts on users.id = posts.user_id
WHERE views > 1000
Efficient
SELECT users.* FROM users
WHERE EXISTS (
SELECT 1 FROM posts
WHERE views > 1000 AND user_id = users.id
)
8. Create joins with INNER JOIN (not WHERE)
Some SQL developers prefer to make joins with WHERE clauses, such as the following:
SELECT Customers.CustomerID, Customers.Name, Sales.LastSaleDate FROM Customers, Sales WHERE Customers.CustomerID = Sales.CustomerID
This type of join creates a Cartesian Join, also called a Cartesian Product or CROSS JOIN.
In a Cartesian Join, all possible combinations of the variables are created.
In this example, if we had 1,000 customers with 1,000 total sales, the query would first generate 1,000,000 results, then filter for the 1,000 records WHERE CustomerID is correctly joined.
This is an inefficient use of database resources, as the database has done 100x more work than required.
Cartesian Joins are especially problematic in large-scale databases, because a Cartesian Join of two large tables could create billions or trillions of results.
To prevent creating a Cartesian Join, use INNER JOIN instead:
SELECT Customers.CustomerID, Customers.Name, Sales.LastSaleDate FROM Customers INNER JOIN Sales ON Customers.CustomerID = Sales.CustomerID
The database would only generate the 1,000 desired records where CustomerID is equal.
Some DBMS systems are able to recognize WHERE joins and automatically run them as INNER JOINs instead. In those DBMS systems, there will be no difference in performance between a WHERE join and INNER JOIN. However, INNER JOIN is recognized by all DBMS systems.
9. Use WHERE instead of HAVING to define filters
The goal of an efficient query is to pull only the required records from the database. Per the SQL Order of Operations, HAVING statements are calculated after WHERE statements. If the intent is to filter a query based on conditions, a WHERE statement is more efficient.
For example, let’s assume 200 sales have been made in the year 2016, and we want to query for the number of sales per customer in 2016.
SELECT Customers.CustomerID, Customers.Name, Count(Sales.SalesID)
FROM Customers
INNER JOIN Sales
ON Customers.CustomerID = Sales.CustomerID
GROUP BY Customers.CustomerID, Customers.Name
HAVING Sales.LastSaleDate BETWEEN #1/1/2016# AND #12/31/2016#
This query would pull 1,000 sales records from the Sales table, then filter for the 200 records generated in the year 2016, and finally count the records in the dataset.
In comparison, WHERE clauses limit the number of records pulled:
SELECT Customers.CustomerID, Customers.Name, Count(Sales.SalesID)
FROM Customers
INNER JOIN Sales
ON Customers.CustomerID = Sales.CustomerID
WHERE Sales.LastSaleDate BETWEEN #1/1/2016# AND #12/31/2016#
GROUP BY Customers.CustomerID, Customers.Name
This query would pull the 200 records from the year 2016, and then count the records in the dataset. The first step in the HAVING clause has been completely eliminated.
HAVING should only be used when filtering on an aggregated field. In the query above, we could additionally filter for customers with greater than 5 sales using a HAVING statement.
SELECT Customers.CustomerID, Customers.Name, Count(Sales.SalesID)
FROM Customers
INNER JOIN Sales
ON Customers.CustomerID = Sales.CustomerID
WHERE Sales.LastSaleDate BETWEEN #1/1/2016# AND #12/31/2016#
GROUP BY Customers.CustomerID, Customers.Name
HAVING Count(Sales.SalesID) > 5
10. Avoid anti-join
Inefficient
SELECT * FROM tickets
WHERE flight_no NOT IN
(SELECT flight_no FROM flights WHERE terminal = 'T1')
Efficient
SELECT * FROM tickets
EXCEPT
SELECT * FROM tickets
WHERE flight_no IN
(SELECT flight_no FROM flights WHERE terminal = 'T1')
11. Use UNION ALL instaed of UNION if possible
If you know that all of the records returned by UNION are going to be unique, use UNION ALL; it will be faster. This is especially relevant for larger datasets.