Nodejs System Infrastructure
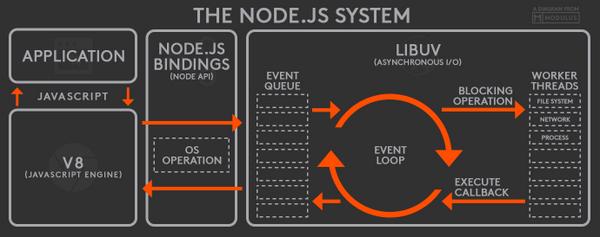
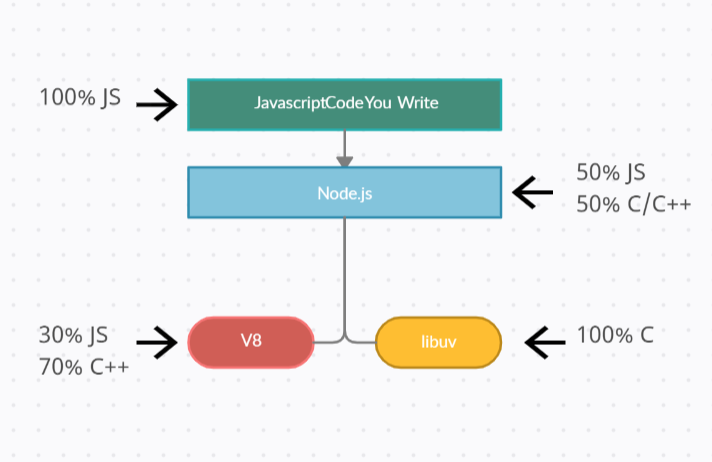
Dependencies
V8
將 js 程式碼轉變成可以在各個平台和機器上運行的機器碼
libuv
提供 nodejs 存取作業系統各種特性的能力,包括檔案系統、socket 等。利用系統提供的事件驅動模組來解決網路非同步 IO,利用執行緒池解決檔案 IO。另外也實作了定時器,對進程,線程等使用進行了封裝
llhttp
更高效能、維護性更好的 http 解析器
c-ares
對於一些非同步 DNS 解析,nodejs 使用了該 C 函式庫。在 js 層面上露出的便是 DNS 模組中的 resolve()族函數
OpenSSL
在 tls 和密碼模組中都得到了廣泛的應用。它提供了經過嚴密測試的許多加密功能的實現,現代 web 依賴這些功能來實現安全性
zlib
為了實現快速得壓縮和解壓縮,nodejs 依賴工業標準的 zlib 庫,也因其在 gzip 和 libpng 中的使用而聞名。nodejs 用 zlib 創建同步的、或非同步或串流的壓縮和解壓縮介面。
npm
套件管理工具
How Nodejs Works?
Node is to give you a nice consistent API for getting access to functionality that is ultimately implemented inside V8 and libuv.
Node.js uses a small number of threads to handle many clients. In Node.js there are two types of threads: one Event Loop (aka the main loop, main thread, event thread, etc.), and a pool of k Workers in a Worker Pool (aka the threadpool).
What code runs on the Event Loop?
When they begin, Node.js applications first complete an initialization phase, require'ing modules and registering callbacks for events. Node.js applications then enter the Event Loop, responding to incoming client requests by executing the appropriate callback. This callback executes synchronously, and may register asynchronous requests to continue processing after it completes. The callbacks for these asynchronous requests will also be executed on the Event Loop.
The Event Loop will also fulfill the non-blocking asynchronous requests made by its callbacks, e.g., network I/O.
In summary, the Event Loop executes the JavaScript callbacks registered for events, and is also responsible for fulfilling non-blocking asynchronous requests like network I/O.
Don't block the Event Loop
The Event Loop notices each new client connection and orchestrates the generation of a response. All incoming requests and outgoing responses pass through the Event Loop. This means that if the Event Loop spends too long at any point, all current and new clients will not get a turn.
You should make sure you never block the Event Loop. In other words, each of your JavaScript callbacks should complete quickly. This of course also applies to your await's, your Promise.then's, and so on.
A good way to ensure this is to reason about the "computational complexity" of your callbacks. If your callback takes a constant number of steps no matter what its arguments are, then you'll always give every pending client a fair turn. If your callback takes a different number of steps depending on its arguments, then you should think about how long the arguments might be.
Blocking the Event Loop: Node.js core modules
Several Node.js core modules have synchronous expensive APIs, including:
These APIs are expensive, because they involve significant computation (encryption, compression), require I/O (file I/O), or potentially both (child process). These APIs are intended for scripting convenience, but are not intended for use in the server context. If you execute them on the Event Loop, they will take far longer to complete than a typical JavaScript instruction, blocking the Event Loop.
Blocking the Event Loop: JSON DOS
JSON.parse and JSON.stringify are other potentially expensive operations. While these are O(n) in the length of the input, for large n they can take surprisingly long.
If your server manipulates JSON objects, particularly those from a client, you should be cautious about the size of the objects or strings you work with on the Event Loop.
Example: JSON blocking. We create an object obj of size 2^21 and JSON.stringify it, run indexOf on the string, and then JSON.parse it. The JSON.stringify'd string is 50MB. It takes 0.7 seconds to stringify the object, 0.03 seconds to indexOf on the 50MB string, and 1.3 seconds to parse the string.
var obj = { a: 1 };
var niter = 20;
var before, str, pos, res, took;
for (var i = 0; i < niter; i++) {
obj = { obj1: obj, obj2: obj }; // Doubles in size each iter
}
before = process.hrtime();
str = JSON.stringify(obj);
took = process.hrtime(before);
console.log("JSON.stringify took " + took);
before = process.hrtime();
pos = str.indexOf("nomatch");
took = process.hrtime(before);
console.log("Pure indexof took " + took);
before = process.hrtime();
res = JSON.parse(str);
took = process.hrtime(before);
console.log("JSON.parse took " + took);
There are npm modules that offer asynchronous JSON APIs. See for example:
- JSONStream, which has stream APIs.
- Big-Friendly JSON, which has stream APIs as well as asynchronous versions of the standard JSON APIs using the partitioning-on-the-Event-Loop paradigm outlined below.
What code runs on the Worker Pool?
The Worker Pool of Node.js is implemented in libuv (docs), which exposes a general task submission API.
Node.js uses the Worker Pool to handle "expensive" tasks. This includes I/O for which an operating system does not provide a non-blocking version, as well as particularly CPU-intensive tasks.
These are the Node.js module APIs that make use of this Worker Pool:
- I/O-intensive
- DNS:
dns.lookup(),dns.lookupService(). - File System: All file system APIs except
fs.FSWatcher()and those that are explicitly synchronous use libuv's threadpool.
- DNS:
- CPU-intensive
Don't block the Worker Pool
Node.js has a Worker Pool composed of k Workers. If you are using the Offloading paradigm discussed above, you might have a separate Computational Worker Pool, to which the same principles apply. In either case, let us assume that k is much smaller than the number of clients you might be handling concurrently. This is in keeping with the "one thread for many clients" philosophy of Node.js, the secret to its scalability.
As discussed above, each Worker completes its current Task before proceeding to the next one on the Worker Pool queue.
Now, there will be variation in the cost of the Tasks required to handle your clients' requests. Some Tasks can be completed quickly (e.g. reading short or cached files, or producing a small number of random bytes), and others will take longer (e.g reading larger or uncached files, or generating more random bytes). Your goal should be to minimize the variation in Task times, and you should use Task partitioning to accomplish this.
Event Loop
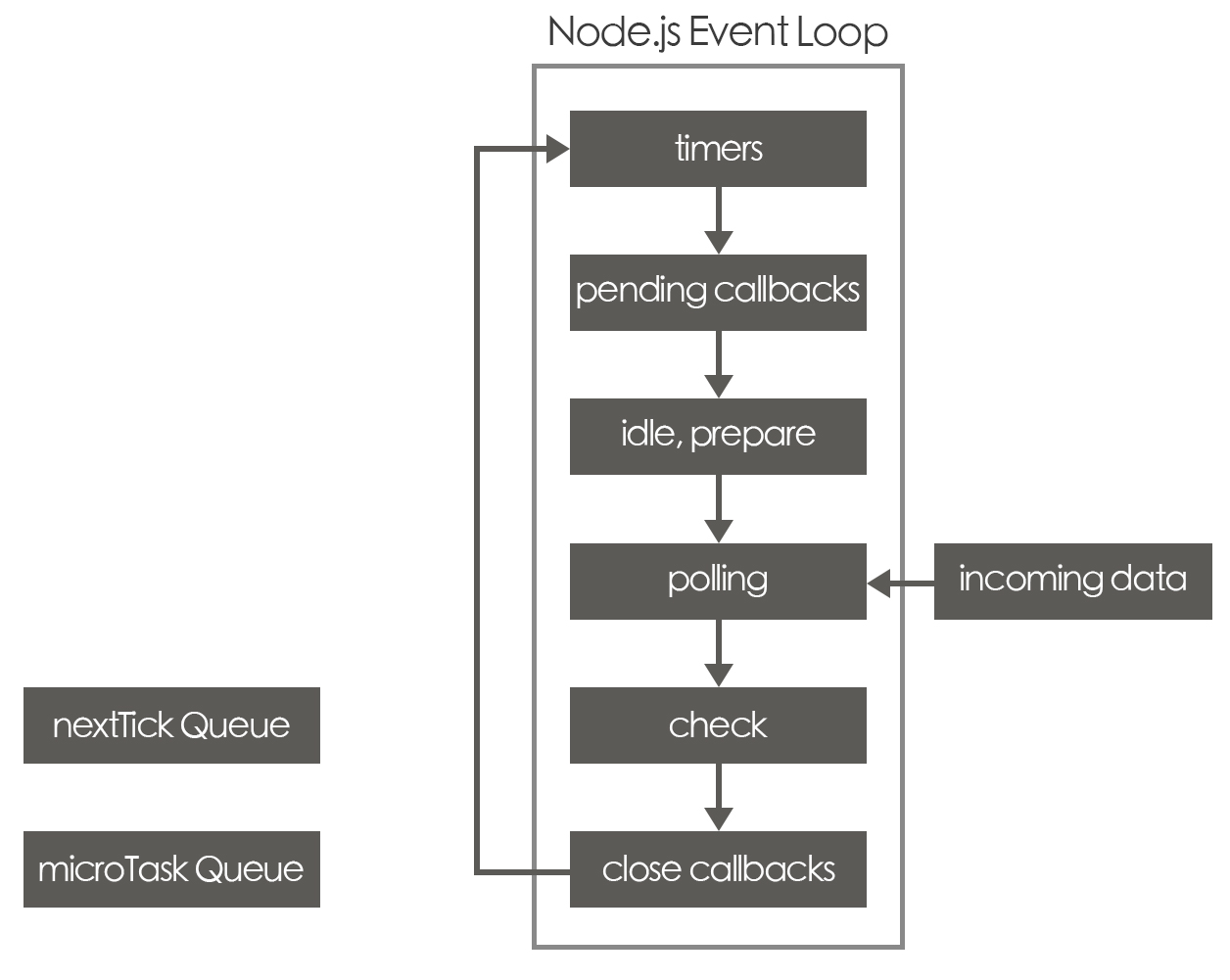
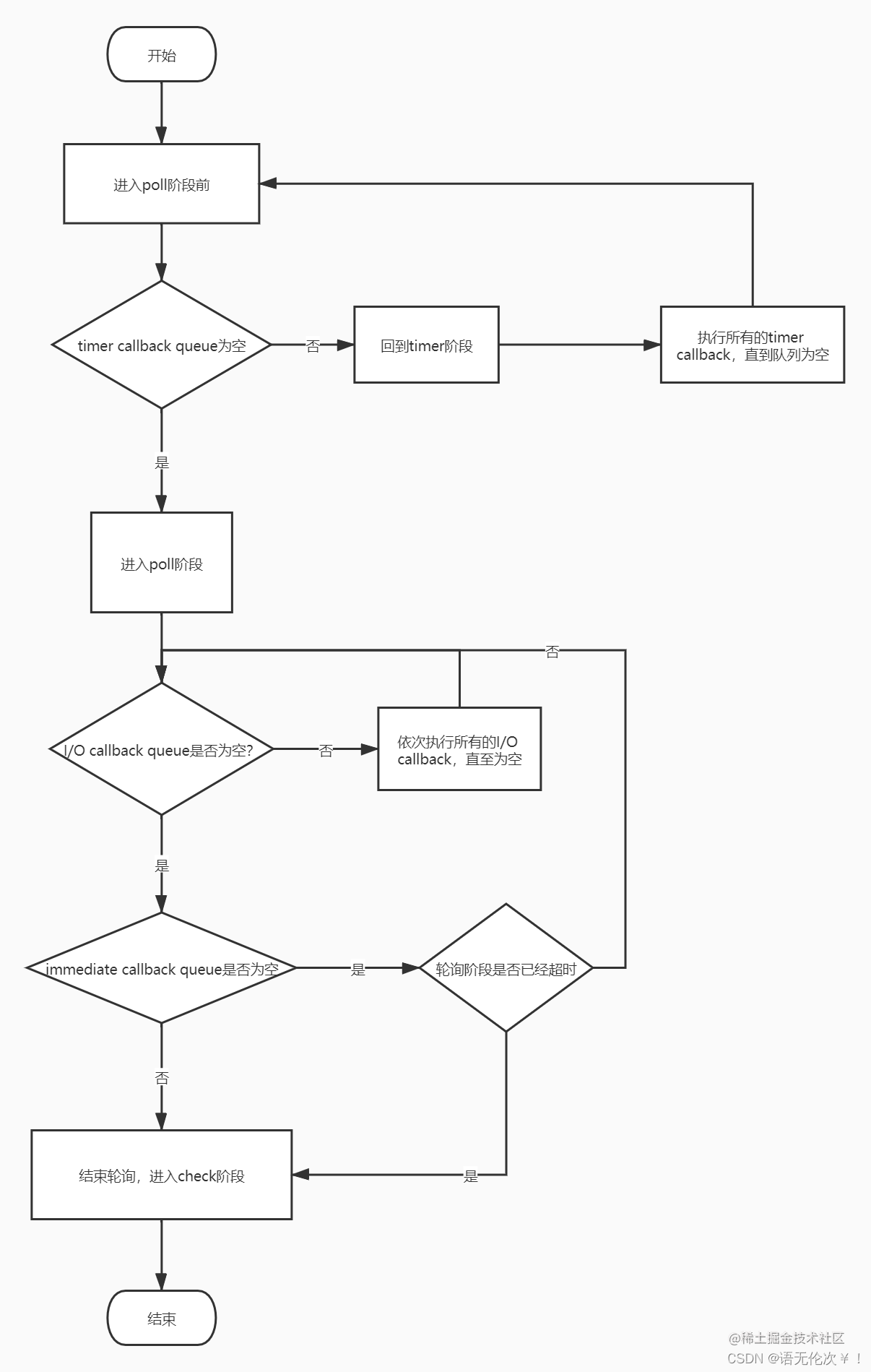
macrotask queue
Timers
會被丟到這個 queue 的事件有setTimeout()跟setInterval(),當所設定的時間倒數完畢時,計時器的 callback 會被丟來這裡等待執行。
Pending callbacks
這個 queue 主要是給作業系統層級使用的,像是傳輸過程中的 TCP errors,socket 連線收到了ECONNREFUSED,他的 callback 就會被丟來這裡。
Idle, prepare
這個 queue 連官方的文件都是說給內部使用的,並沒有在文件中多做說明,所以這個 queue 可以先忽略。
Polling
當 Node.js 的 app 在運行時有新的 I/O 資料進來可以被讀取時,例如會用到串流有提供的.on('data', callback),這時他的 callback 就會被放在這個 queue 等待被執行。
Check
還記得我們有一個也是有關時間的setImmediate()還沒講到,他的 callback 就是排在這裡的。
Close callbacks
當我們今天需要關閉連線、檔案等等的操作時,例如socket.on('close', callback),只要是有關"關閉"的動作的 callback 就會來這裡。
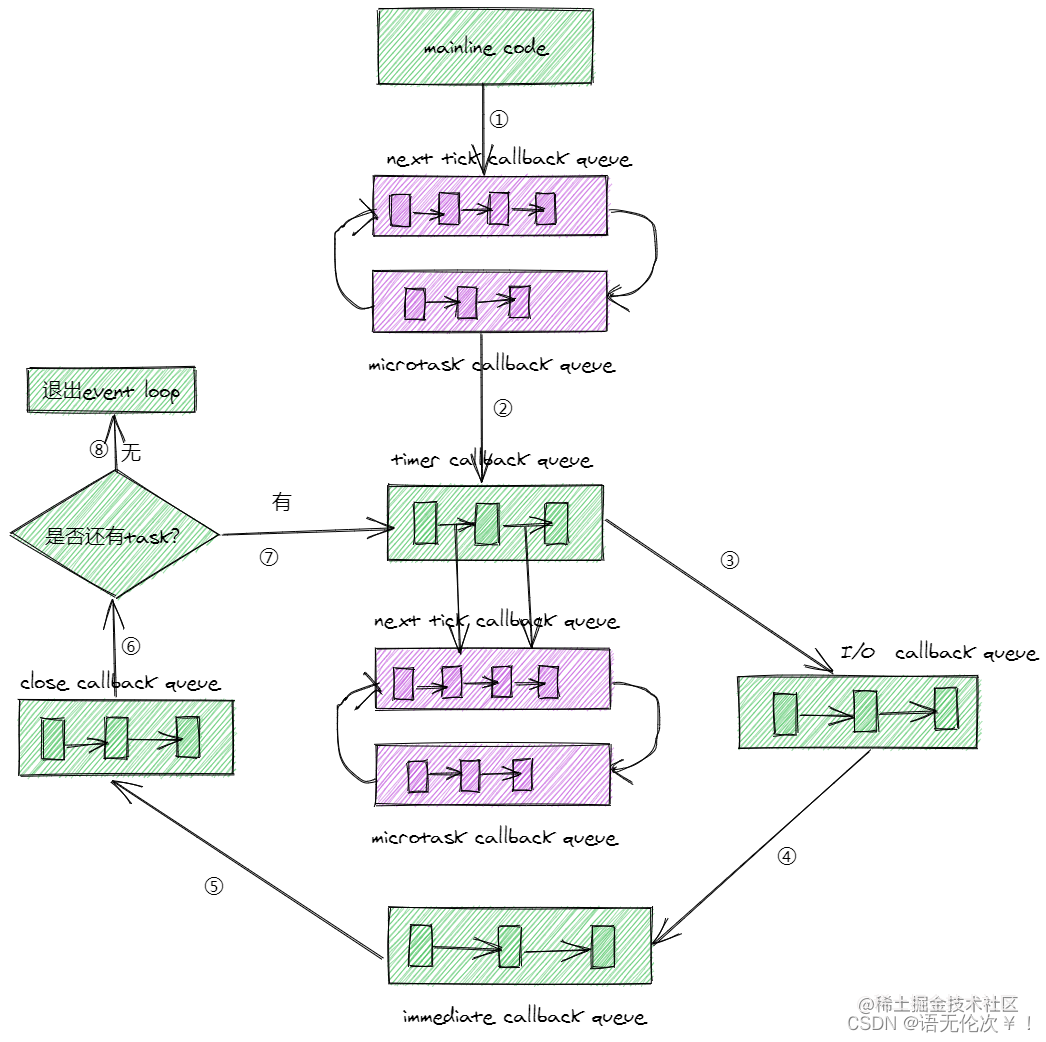
MicroTask Queue
這是優先層級第二高的 queue,當我們在程式中使用的 promise 狀態有從 pending 轉變為 resolve 或 reject 時,resolve 或 reject 所執行的 callback 會被排在這個 queue。注意是 resolve 或 reject 所執行的 callback 喔,例如 Promise.resolve().then(CALLBACK)的那個 CALLBACK。
NextTick Queue
這是優先層級第一高的 queue,所有給定的process.nextTick()的 callback 都會來這裡。只要這個 queue 有東西,Event Loop 就會優先執行這裡的 callback,即便 timer 到期也一樣。
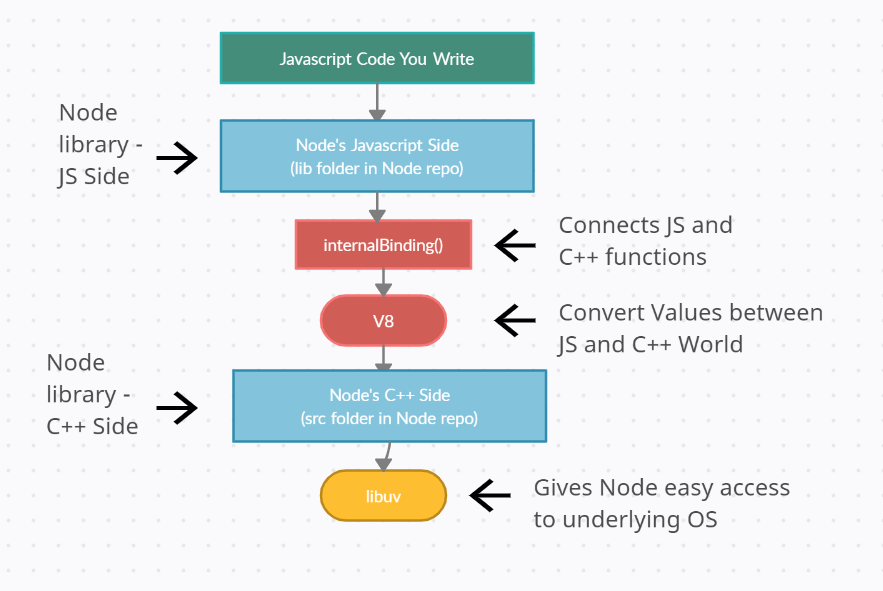
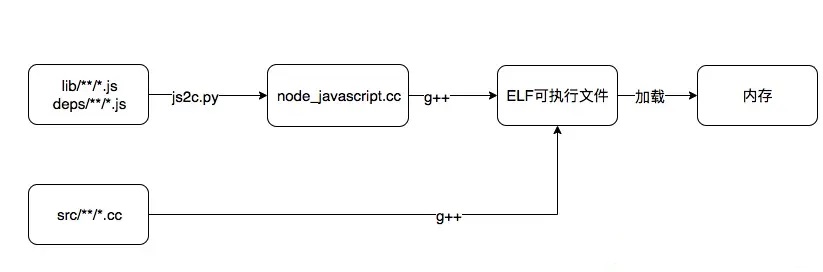
Git Repository
lib directory : Contains all the javascript definitions of functions and modules that you require into your projects.
So you can think of this lib folder as being like the javascript world or the javascript side of Node
src directory: Inside is the C++ implementation of all those functions.
So src directory is where Node actually pulls in libuv and the V8 project and actually flushes out the implementation of all the modules that you are used to like FS and HTTP
Compiling Process
Tools to help diagnose and pinpoint Node.js performance issues: Clinic.js
- Doctor: Overview
- Flame: CPU
- Bubbleprof: IO
- HeapProfiler: Memory
Reference
- A toolkit to make creating and working with streams easy
- Don't Block the Event Loop (or the Worker Pool)
- Nodejs 是如何與 v8 及 libuv 一起合作的?
- Nodejs 如何利用 libuv 實現事件循環和異步
- 完整圖解 Node.js 的 Event Loop(事件迴圈)
- Tools to help diagnose and pinpoint Node.js performance issues
- JavaScript Visualizer
- setTimeout 和 setImmediate 到底是誰先執行,本文讓你徹底理解 Event Loop
- Event Loop 運行機制解析 - Node.js 篇
- 如何理解 Node.js 不是完全的單執行緒的程式(淺析)