MLIR
IR 群雄割據,MLIR 一統天下
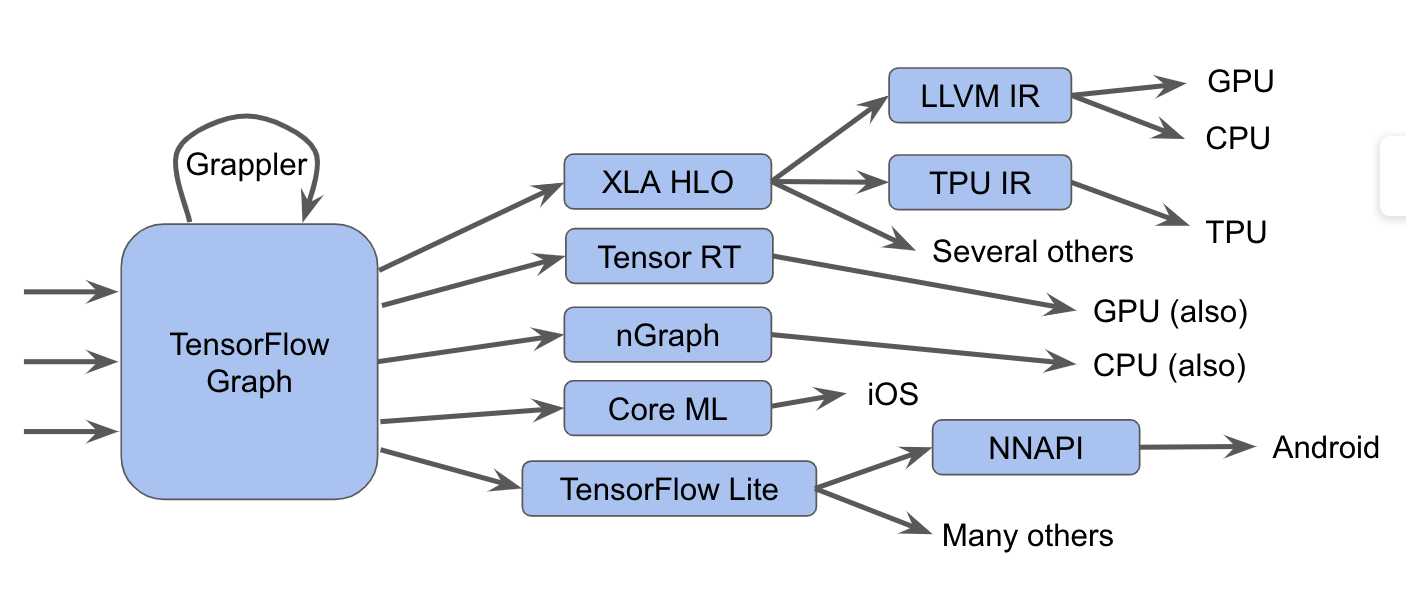
從原始程式碼到目標機器碼,要經過一系列的抽像以及分析,通過 Lowering Pass 來實現從一個 IR 到另一個 IR 的轉換,這樣的過程中會存在有些行為重複實現的情況,也就導致了轉換效率低的問題。通俗的說,不同 IR 間沒有默契。因為語言不通,為了解決這種亂象,MLIR 學 LLVM 一樣,統一了 IR,讓不同的 IR 可以藉由這個統一的 IR 相互理解。而 MLIR 利用 Dialect(方言),讓每個 IR 學習這個方言,大家就可以順利的互相溝通了。 和 LLVM 一樣,一統編譯器開發的亂象。
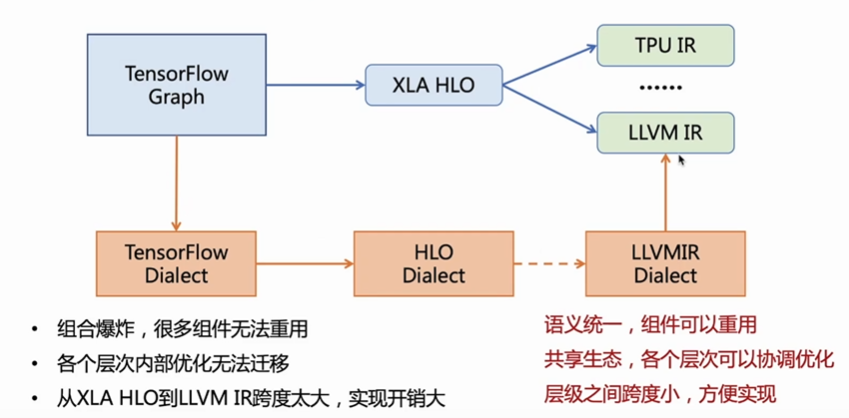
Dialects 就是 MLIR 的方言,我們可以定義很多不同的方言來表示不同的抽象,例如: 先把 tensorflow graph 翻譯成用 tensorflow dialect 描述的 MLIR 的檔案。得到 MLIR 的檔案後,tensorflow dialect 再轉成 HLO Dialect,再進行逐級向下抽象 (Multi-Level 的真意),每一個 pass 可以對某個部分進行最佳化,得到 LLVMIR Dialect,最後再轉換成真正的 LLVM IR 進行後續的處理。
不同的方言也可以互相轉換,因為都是在同一個 MLIR 的規範下。Dialects 是將所有的 IR 放在了同一個命名空間中,分別對每個 IR 定義對應的產生式以及綁定相應的操作,從而生成一個 MLIR 的模型。整個的編譯過程,從原始程式碼生成 AST,借助 Dialects 遍歷 AST,產生 MLIR 的表達式,此處可為多層 IR 通過 Lowering Pass 依次進行分析,最後經過 MLIR 分析器,生成目標程式碼。MLIR 支持此種插件架構,可以使用它擴展幾乎所有 MLIR 功能。