SELECT 執行流程
MySQL 架構
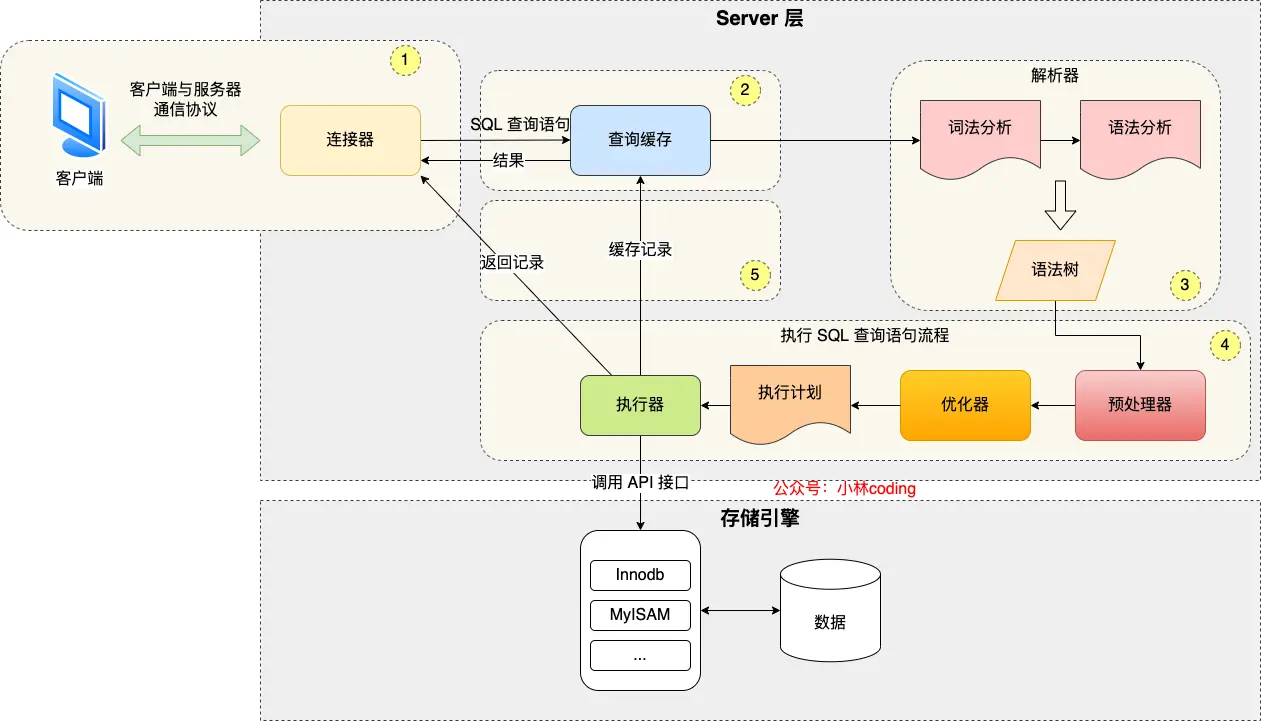
Server 層
負責建立連接、分析和執行 SQL。主要包括連接器,查詢緩存、解析器、預處理器、優化器、執行器。
內置函數(日期、時間、數學和加密函數)和所有跨儲存引擎的功能(SP、Trigger、View)也都是在 Server 層實現。
Storage Enigne 層
負責資料的儲存和提取。支援 InnoDB、MyISAM、etc. 不同的 Storage Engine 共用一個 Server 層。
我們常說的索引資料結構,就是在這實現的,不同的 Storage Engine 支援的索引類型也不同,像 InnoDB 預設支援的索引類型是 B+ 樹。
1. 連接器
如果你在 Linux 操作系統裡要使用 MySQL,那你第一步肯定是要先連接 MySQL 服務,然後才能執行 SQL 語句。
連接的過程需要先經過 TCP 三次握手,因為 MySQL 是基於 TCP 協議進行傳輸的,如果 MySQL 服務並沒有啟動,則會收到如下的報錯:

如果 MySQL 服務正常運行,完成 TCP 連接的建立後,連接器就要開始驗證你的用戶名和密碼,如果用戶名或密碼不對,就收到一個 Access denied for user 的錯誤。

如果用戶密碼都沒有問題,連接器就會獲取該用戶的權限,然後保存起來,後續該用戶在此連接裡的任何操作,都會基於連接開始時讀到的權限進行權限邏輯的判斷。
Question
如何查看 MySQL 被多少個客戶端連接?
如果你想知道當前 MySQL 服務被多少個客戶端連接了,你可以執行 show processlist 命令進行查看。
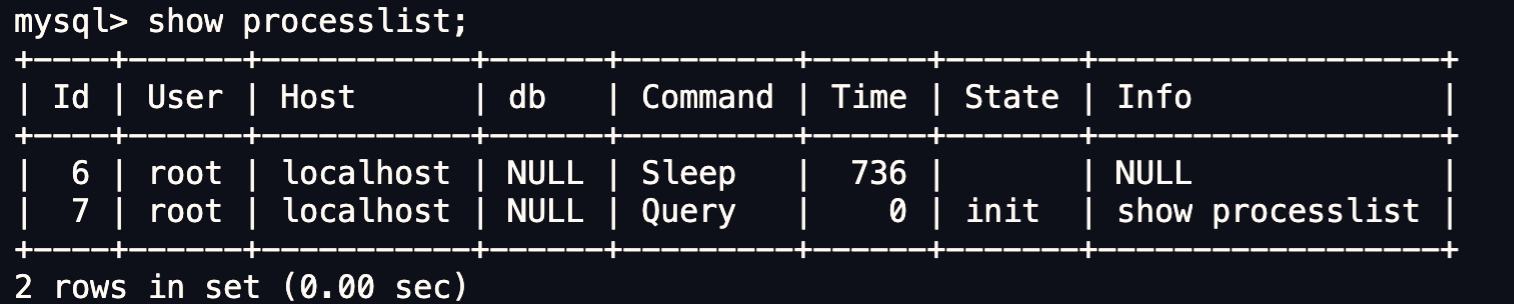
比如上圖的顯示結果,共有兩個用戶名為 root 的用戶連接了 MySQL 服務,其中 id 為 6 的用戶的 Command 列的狀態為 Sleep,這意味著該用戶連接完 MySQL 服務就沒有再執行過任何命令,也就是說這是一個空閒的連接,並且空閒的時長是 736 秒。
Question
空閒的連接會一直佔用著嗎?
當然不是了,MySQL 定義了空閒連接的最大空閒時長,由 wait_timeout 參數控制,默認值是 8 小時(28880 秒),如果空閒連接超過了這個時間,連接器就會自動將它斷開。
mysql> show variables like 'wait_timeout';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wait_timeout | 28800 |
+---------------+-------+
1 row in set (0.00 sec)
我們自己也可以手動斷開空閒的連接,使用的是 kill connection +id 的命令。
mysql> kill connection +6;
Query OK, 0 rows affected (0.00 sec)
一個處於空閒狀態的連接被服務端主動斷開後,這個客戶端並不會馬上知道,等到客戶端在發起下一個請求的時候,才會收到這樣的報錯 ERROR 2013 (HY000): Lost connection to MySQL server during query。
Question
MySQL 的連接數有限制嗎?
MySQL 服務支持的最大連接數由 max_connections 參數控制,MySQL 服務默認是 151 個,超過這個值,系統就會拒絕接下來的連接請求,並報錯提示 Too many connections。
mysql> show variables like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
1 row in set (0.00 sec)
MySQL 的連接也跟 HTTP 一樣,有短連接和長連接的概念。
使用長連接的好處就是可以減少建立連接和斷開連接的過程,所以一般是推薦使用長連接。
但是如果長連接累計過多,將導致 MySQL 服務佔用記憶體太大,有可能會被系統強制殺掉,發生 MySQL 服務異常重啟的現象。
Question
怎麼解決長連接佔用記憶體的問題?
有兩種解決方式:
-
定期斷開長連接。既然斷開連接後就會釋放連接佔用的記憶體資源,那麼我們可以定期斷開長連接。
-
客戶端主動重置連接。MySQL 5.7 版本實現
mysql_reset_connection()函數的接口,這是接口函數不是命令,當客戶端執行了一個很大的操作後,在代碼裡調用mysql_reset_connection函數來重置連接,達到釋放記憶體的效果。這個過程不需要重連和重新做權限驗證,但是會將連接恢復到剛剛創建完時的狀態。
2. 查詢緩存
Warning
Deprecated since MySQL 8.0
連接器的工作完成後,客戶端就可以向 MySQL 服務發送 SQL 語句了,MySQL 服務收到 SQL 語句後,就會解析出 SQL 語句的第一個字段,看看是什麼類型的語句。
如果 SQL 是查詢語句(select 語句),MySQL 就會先去查詢緩存( Query Cache )裡找資料,看看之前有沒有執行過這一條命令,這個查詢緩存是以 key-value 形式保存在記憶體中的,key 為 SQL 查詢語句,value 為 SQL 語句查詢的結果。
如果查詢的語句命中緩存,就會直接返回 value 給客戶端。否則就往下繼續執行,執行完後會將結果存入緩存。
對於更新比較頻繁的表,緩存的命中率是很低的,因為只要一個表有更新操作,這個表的緩存就會被清空。如果剛緩存了一個查詢結果很大的資料,還沒被使用,又馬上有新的操作更新表,緩存就被清空了。
因此,MySQL 8.0 版本直接將查詢緩存刪掉了。MySQL 8.0 之前的版本,如果想關閉緩存,我們可將參數 query_cache_type 設置成 DEMAND。
3. 解析器
在正式執行 SQL 查詢語句之前, MySQL 會先對 SQL 語句做解析,這個工作交由「解析器」來完成。
Question
解析器做了什麼事情?
-
詞法分析。MySQL 會根據輸入的字符串識別出關鍵字,構建 SQL 語法樹,方便後面模塊獲取 SQL 類型、表名、字段名、 where 條件。
-
語法分析。根據詞法分析的結果,語法解析器會根據語法規則,判斷 SQL 語句是否滿足 MySQL 語法。
如果我們輸入的 SQL 語句語法不對,就會在解析器這個階段報錯。比如,下面這條查詢語句,把 from 寫成了 form,這時 MySQL 解析器就會報錯。

4. 預處理器
Question
預處理器做了什麼事情?
- 檢查 SQL 查詢語句中的表或者字段是否存在
- 將
select *中的*符號,擴展為表上的所有列
5. 優化器
經過預處理階段後,會由優化器負責制定 SQL 查詢語句的執行方案。
Info
在表裡面有多個索引的時候,優化器會考量查詢成本,決定要使用哪個索引。
想知道優化器選擇了哪個索引,可以在查詢語句最前面加上 explain ,這樣就會輸出 SQL 語句的執行計劃。
6. 執行器
確定了執行方案,接下來 MySQL 就真正開始執行語句了。在執行的過程中,執行器會和 Storage Engine 互動,互動是以記錄為單位的。
以下介紹兩種執行過程:
- 主鍵索引查詢
- 全表掃描
主鍵索引查詢
select * from product where id = 1;
這條查詢語句的查詢條件用到了主鍵索引,而且是等值查詢,同時主鍵 id 是唯一,不會有 id 相同的記錄,所以優化器決定選用訪問類型為 const 進行查詢,也就是使用主鍵索引查詢一條記錄,那麼執行器與儲存引擎的執行流程是這樣的:
- 執行器第一次查詢,會調用 read_first_record 函數指針指向的函數,因為優化器選擇的訪問類型為 const,這個函數指針被指向為 InnoDB 引擎索引查詢的接口,把條件
id = 1交給儲存引擎,讓儲存引擎定位符合條件的第一條記錄 - 儲存引擎通過主鍵索引的 B+ 樹結構定位到 id = 1 的第一條記錄,如果記錄是不存在的,就會向執行器上報記錄找不到的錯誤,然後查詢結束。如果記錄是存在的,就會將記錄返回給執行器
- 執行器從儲存引擎讀到記錄後,接著判斷記錄是否符合查詢條件,如果符合則發送給客戶端,如果不符合則跳過該記錄。查一次,但是這次因為不是第一次查詢了,所以會調用 read_record 函數指針指向的函數,因為優化器選擇的訪問類型為 const,這個函數指針被指向為一個永遠返回 -1 的函數,所以當調用該函數的時候,執行器就退出循環,也就是結束查詢了
全表掃描
select * from product where name = 'iphone';
這條查詢語句的查詢條件沒有用到索引,所以優化器決定選用訪問類型為 ALL 進行查詢,也就是全表掃描的方式查詢,那麼這時執行器與儲存引擎的執行流程是這樣的:
- 執行器第一次查詢,會調用 read_first_record 函數指針指向的函數,因為優化器選擇的訪問類型為 all,這個函數指針被指向為 InnoDB 引擎全掃描的接口,讓儲存引擎讀取表中的第一條記錄
- 執行器會判斷讀到的這條記錄的 name 是不是 iphone,如果不是則跳過;如果是則將記錄發給客戶的(是的沒錯,Server 層每從儲存引擎讀到一條記錄就會發送給客戶端,之所以客戶端顯示的時候是直接顯示所有記錄的,是因為客戶端是等查詢語句查詢完成後,才會顯示出所有的記錄)
- 執行器查詢的過程是一個 while 循環,所以還會再查一次,會調用 read_record 函數指針指向的函數,因為優化器選擇的訪問類型為 all,read_record 函數指針指向的還是 InnoDB 引擎全掃描的接口,所以接著向儲存引擎層要求繼續讀剛才那條記錄的下一條記錄,儲存引擎把下一條記錄取出後就將其返回給執行器(Server 層),執行器繼續判斷條件,不符合查詢條件即跳過該記錄,否則發送到客戶端
- 一直重複上述過程,直到儲存引擎把表中的所有記錄讀完,然後向執行器(Server 層) 返回了讀取完畢的信息
- 執行器收到儲存引擎報告的查詢完畢的信息,退出循環,停止查詢