為什麼大家說 MySQL 資料庫單表最大兩千萬?
索引的結構
在為什麼 MySQL 採用 B+ 樹來實現索引?有提到索引內部是用 B+ 樹。
假設我們有這麼一張 user 數據表。
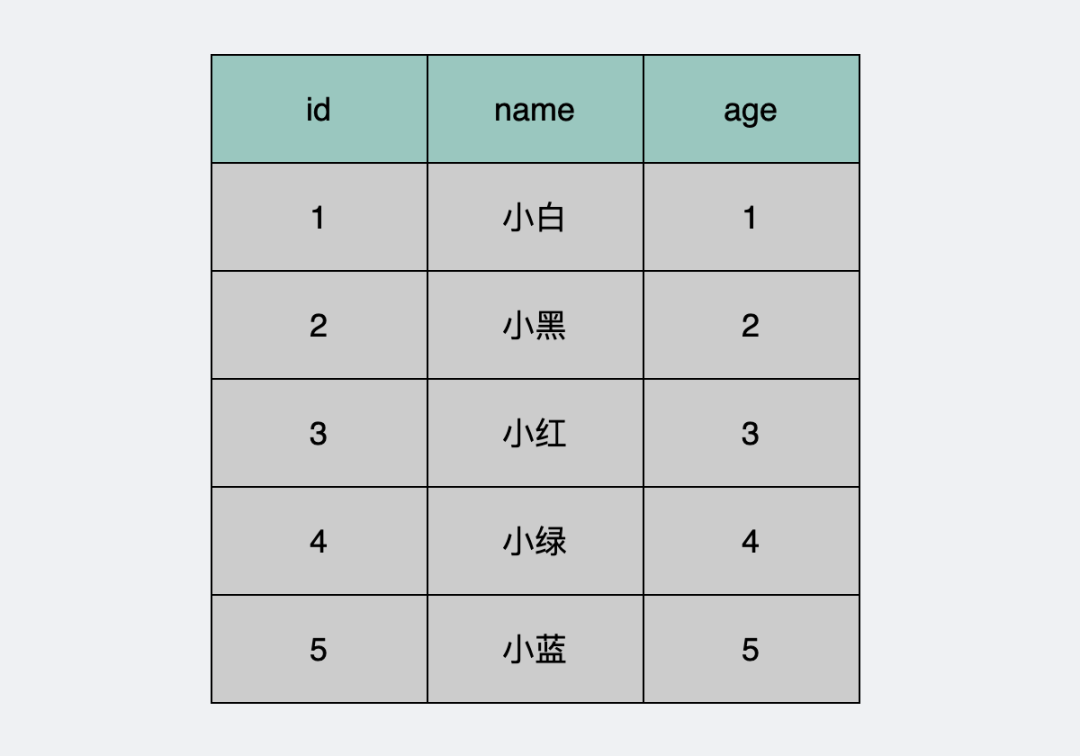
其中 id 是唯一主鍵。
這看起來的一行行數據,為了方便,我們後面就叫它們 record 吧。
這張表看起來就跟個 excel 表格一樣。excel 的數據在磁盤上是一個 xxx.excel 的文件。
而上面 user 表數據,在磁盤上其實也是類似,放在了 user.ibd 文件下。含義是 user 表的 innodb data 文件,專業點,又叫表空間。
雖然在數據表裡,它們看起來是挨在一起的。但實際上在 user.ibd 裡他們被分成很多小份的數據頁,每份大小 16k。
類似於下面這樣。
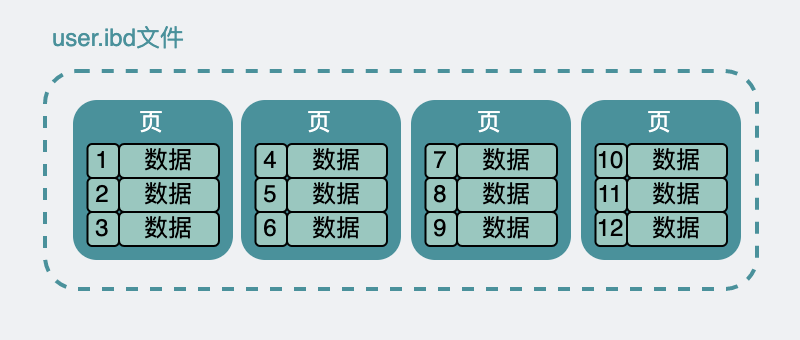
ibd 文件內部有大量的頁
我們把視角聚焦一下,放到頁上面。
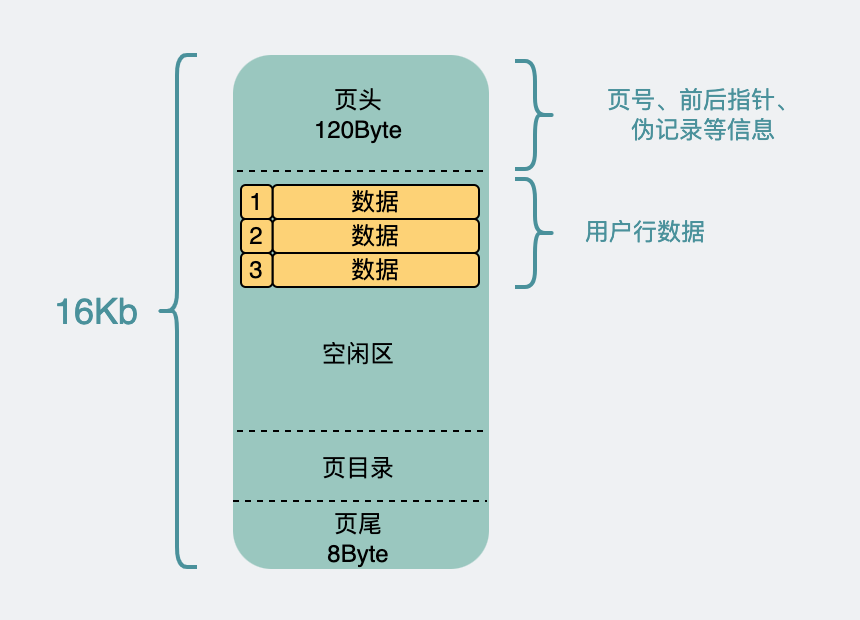
整個頁 16k,不大,但 record 這麼多,一頁肯定放不下,所以會分開放到很多頁裡。並且這 16k,也不可能全用來放 record 對吧。
因為 record 們被分成好多份,放到好多頁裡了,為了唯一標識具體是哪一頁,那就需要引入頁號(其實是一個表空間的地址偏移量)。同時為了把這些數據頁給關聯起來,於是引入了前後指針,用於指向前後的頁。這些都被加到了頁頭裡。
頁是需要讀寫的,16k 說小也不小,寫一半電源線被拔了也是有可能發生的,所以為了保證數據頁的正確性,還引入了校驗碼。這個被加到了頁尾。
那剩下的空間,才是用來放我們的 record 的。而 record 如果行數特別多的話,進入到頁內時挨個遍歷,效率也不太行,所以為這些數據生成了一個頁目錄,具體實現細節不重要。只需要知道,它可以通過二分查找的方式將查找效率從 O(n) 變成 O(lg n)。
如果想查一條 record,我們可以把表空間裡每一頁都撈出來,再把裡面的 record 撈出來挨個判斷是不是我們要找的。
行數量小的時候,這麼操作也沒啥問題。
行數量大了,性能就慢了,於是為了加速搜索,我們可以在每個數據頁裡選出主鍵 id 最小的 record,而且只需要它們的主鍵 id 和所在頁的頁號。組成新的 record ,放入到一個新生成的一個數據頁中,這個新數據頁跟之前的頁結構沒啥區別,而且大小還是 16k。
但為了跟之前的數據頁進行區分。數據頁裡加入了頁層級(page level)的信息,從 0 開始往上算。於是頁與頁之間就有了上下層級的概念,就像下面這樣。
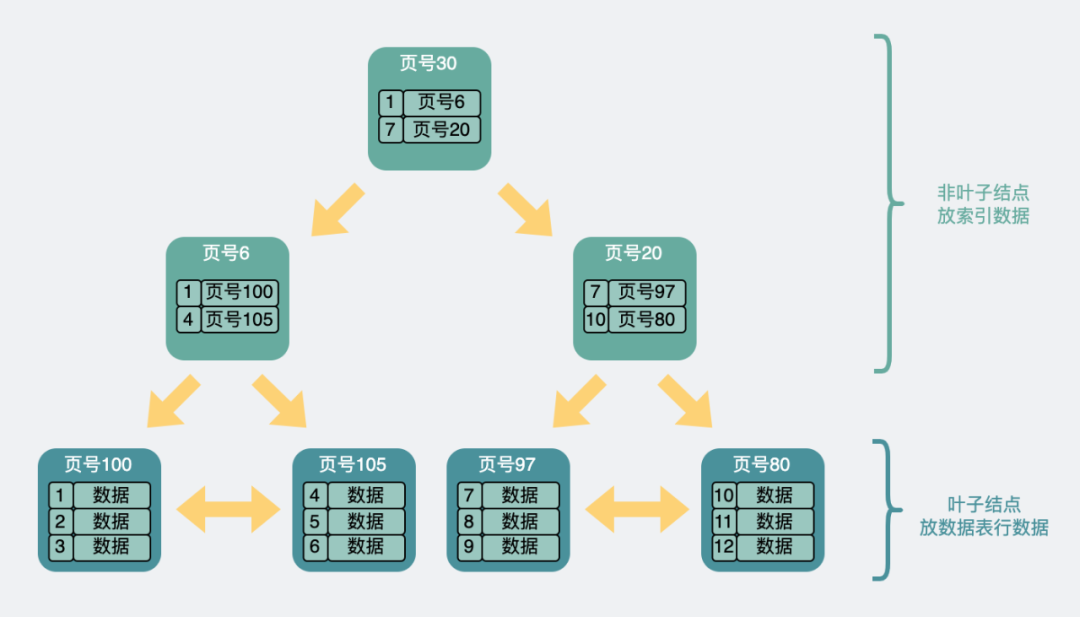
現在我們可以通過這樣一棵 B+ 樹加速查詢,舉個例子。
比方說我們想要查找行數據 5。會先從頂層頁的 record 們入手。record 裡包含了主鍵 id 和頁號(頁地址)。看下圖黃色的箭頭,向左最小 id 是 1,向右最小 id 著的 record 的頁地址就到了 6號 數據頁裡,再判斷 id = 5 > 4,所以肯定在右邊的數據頁裡,於是加載 105 號 數據頁。在數據頁裡找到 id = 5 的數據行,完成查詢。
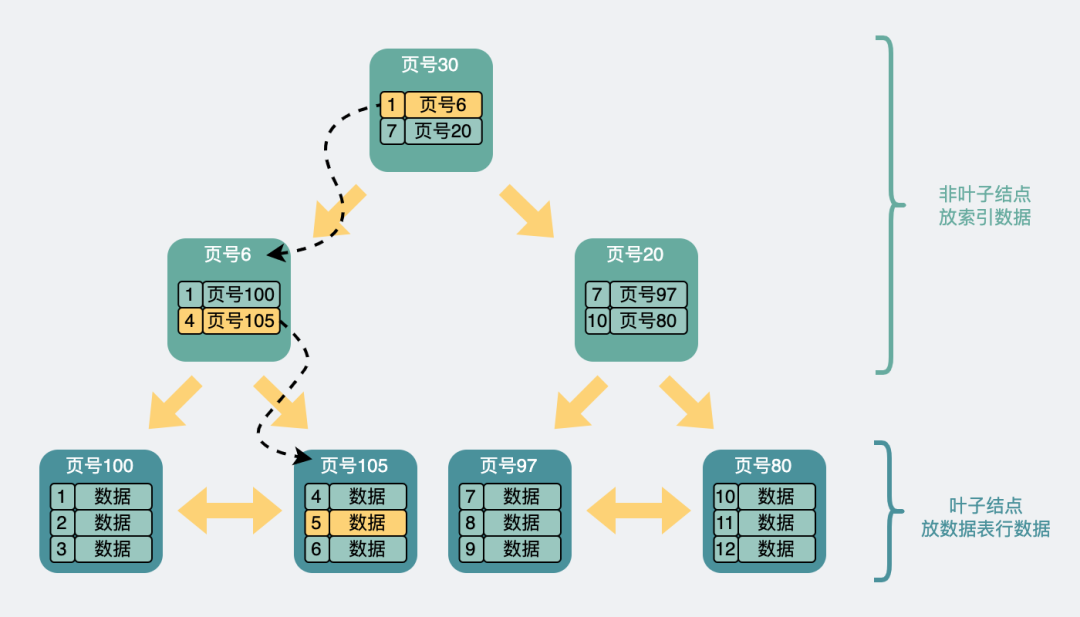
另外需要注意的是,上面的頁的頁號並不是連續的,它們在磁盤裡也不一定是挨在一起的。
這個過程中查詢了三個頁,如果這三個頁都在磁盤中(沒有被提前加載到內存中),那麼最多需要經歷三次磁盤 IO 查詢,它們才能被加載到內存中。
B+ 樹承載的記錄數量
從上面的結構裡可以看出 B+ 樹的最末級葉子節點裡放了 record 數據。而非葉子節點裡則放了用來加速查詢的索引數據。
也就是說,同樣一個 16k 的頁,非葉子節點裡每一條數據都指向一個新的頁,而新的頁有兩種可能。
- 如果是葉子節點的話,那麼裡面放的就是一行行 record 數據。
- 如果是非葉子節點,那麼就會循環繼續指向新的數據頁。
假設
- 非葉子節點內指向其他數據頁的指針數量為
x - 葉子節點內能容納的 record 數量為
y - B+ 樹的層數為
z
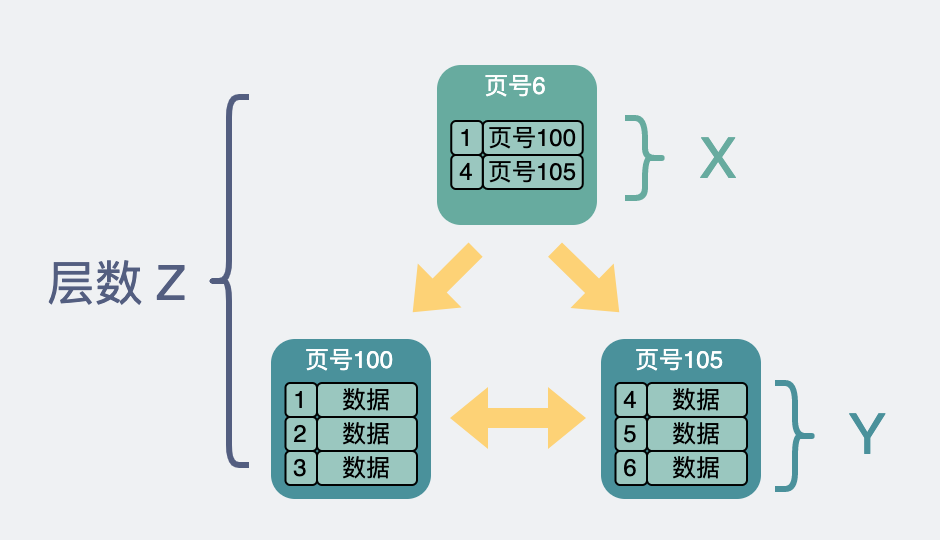
那麼這棵 B+ 樹放的行數據總量即為 (x ^ (z-1)) * y。
x 怎麼算
我們回去看數據頁的結構。
非葉子節點裡主要放索引查詢相關的數據,放的是主鍵和指向頁號。
主鍵假設是 bigint(8 Byte),而頁號在源碼裡叫 FILE_PAGE_OFFSET(4 Byte),那麼非葉子節點裡的一條數據是 12 Byte左右。
整個數據頁 16k, 頁頭頁尾那部分數據全加起來大概 128 Byte,加上頁目錄毛估佔 1k 吧。那剩下的 15k 除以 12 Byte,等於 1280,也就是可以指向 x = 1280 頁。
我們常說的二叉樹指的是一個節點可以發散出兩個新的節點。m 叉樹一個節點能指向 m 個新的節點。這個指向新節點的操作就叫扇出(fanout)。
而上面的 B+ 樹,它能指向 1280 個新的節點,可以說扇出非常高了。
x ~= (pageSize - 頁頭頁尾頁目錄) / (keySize + FILE_PAGE_OFFSET)
y 怎麼算
葉子節點和非葉子節點的數據結構是一樣的,所以也假設剩下 15kb 可以發揮。
葉子節點裡放的是真正的行數據。假設一條行數據 1kb ,所以一頁裡能放 y = 15 行。
y ~= (pageSize - 頁頭頁尾頁目錄) / recordSize
行總數計算
回到 (x ^ (z-1)) * y 這個公式。
已知 x = 1280,y = 15。
假設 B+ 樹是兩層,z = 2。則是(1280 ^ (2-1)) * 15 ≈ 2w
假設 B+樹是三層,z = 3。則是(1280 ^ (3-1)) * 15 ≈ 2.5kw
這個 2.5kw,就是我們常說的單表建議最大行數 2kw 的由來。 畢竟再加一層,數據就大得有點離譜了。三層數據頁對應最多三次磁盤 IO,也比較合理。
行數超過一億就慢了嗎?
上面假設單行數據用了 1kb,所以一個數據頁能放個 15 行數據。
如果我單行數據用不了這麼多,比如只用了 250 byte。那麼單個數據頁能放 60 行數據。
那同樣是三層 B+ 樹,單表支持的行數就是(1280 ^ (3-1)) * 60 ≈ 1億。
這樣即使是一億行數據,其實也就三層 B+ 樹,在這個 B+ 樹裡要查到某行數據,最多也是三次磁盤 IO。所以並不慢。
這就很好的解釋了文章開頭,為什麼單表 1 個億,但查詢性能沒啥大毛病。
B 樹承載的記錄數量
既然都聊到這裡了,我們就順著這個話題多聊一些吧。
我們都知道,現在 mysql 的索引都是 B+樹,而有一種樹,跟 B+ 樹很像,叫 B 樹,也叫 B-樹。
它跟 B+ 樹最大的區別在於,B+ 樹只在葉子節點處放數據表行數據,而 B 樹則會在葉子和非葉子節點上都放。
於是,B 樹的結構就類似這樣
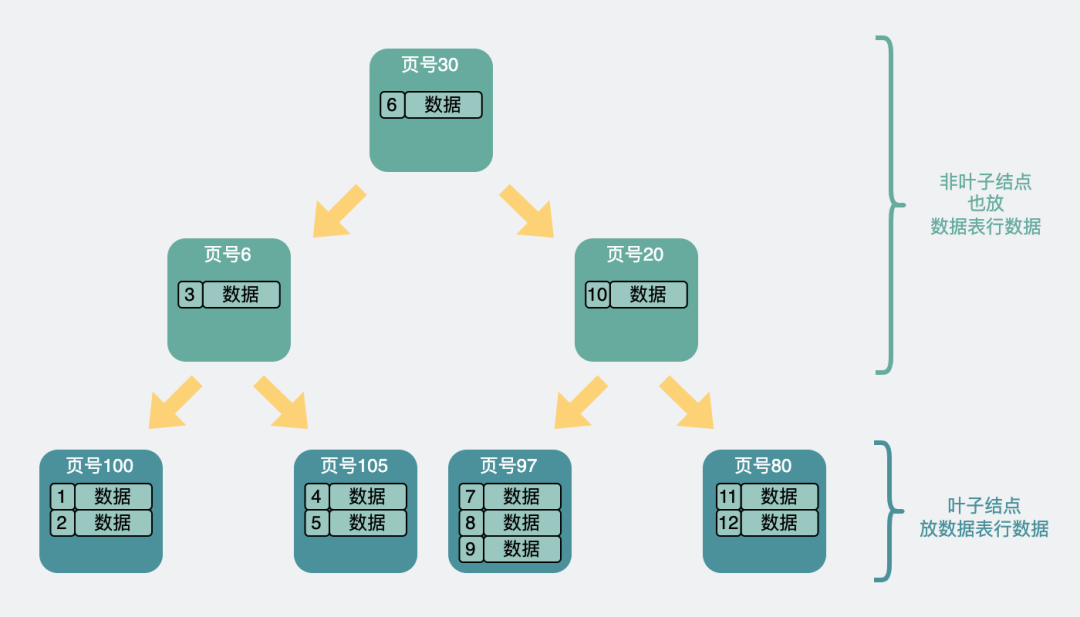
B 樹將行數據都存在非葉子節點上,假設每個數據頁還是 16kb,掐頭去尾每頁剩 15kb,並且一條數據表行數據還是佔 1kb,就算不考慮各種頁指針的情況下,也只能放個 15 條數據。數據頁扇出明顯變少了。
計算可承載的總行數的公式也變成了一個等比數列。
15 + 15^2 +15^3 + ... + 15^z
為了能放 2kw 左右的數據,需要 z >= 6。也就是樹需要有 6 層,查一次要訪問 6 個頁。假設這 6 個頁並不連續,為了查詢其中一條數據,最壞情況需要進行 6 次磁盤 IO。
而 B+ 樹同樣情況下放 2kw 數據左右,查一次最多是 3 次磁盤 IO。
磁盤 IO 越多則越慢,這兩者在性能上差距略大。
因此,B+ 樹比 B 樹更適合成為 mysql 的索引。
總結
在考慮分表的時候還是得多關注一下表的實際情況,而不是盲目的認為 2kw 數據就是那個臨界點。
如果面試時談到這問題,我想面試官也並不是想知道這個數字到底是多少,而是想看你如何分析這個問題,看你得出這個數字的過程。